Mycat相关简介:
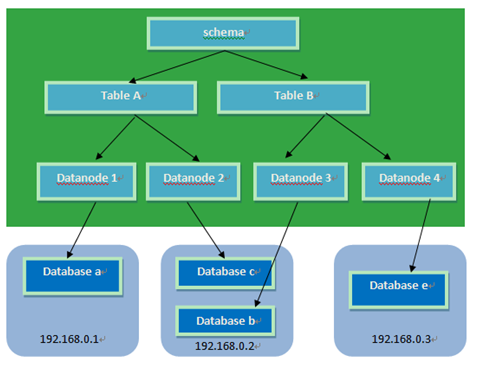
schema:逻辑库,与Mysql中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的"子表(childTable)",子表的分片依赖于与父表的具体分片地址,简单的说,就是属于父表里的某一条记录A的分片规则;是一个字段与函数的捆绑定义,根据这个字段的取值来返回所在存储的分片(DataNode)的序号,每个表格可以定义一个分片规则,分片规则可以灵活扩展,默认提供了基于数字的分片规则,字符串的分片规则等。
dataNode:Mycat的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置俩个DataSource,一主一从,当主机点宕机,系统自动切换到从节点。
dataHost:定义某个物理数据库的访问地址,用于捆绑到dataNode上。
Mycat目前通过配置文件的方式来定义逻辑库和相关配置:
Mycat_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
MYCAT_HOME/conf/rule.xml中定义分片规则;
MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量。如端口等。
关系图:
对数据表进行水平拆分:
对数据量很大的表进行拆分,把这些表按照某种规则将数据存放到不同的数据库中。示例:
schema.xml文件:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- tb_class和tb_student有外键关联关系,可以测试join --> <schema name="test" checkSQLschema="false" sqlMaxLimit="100"> <table name="tb_user" dataNode="dn1,dn2" rule="rule1" primaryKey="id"/> </schema> <dataNode name="dn1" dataHost="mycat1" database="mycat1" /> <dataNode name="dn2" dataHost="mycat2" database="mycat2" /> <dataHost name="mycat1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="host1" url="ip1:3306" user="root" password="123456" /> </dataHost> <dataHost name="mycat2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="host3" url="ip2:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
server.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://org.opencloudb/"> <system> <property name="defaultSqlParser">druidparser</property> </system> <!--帐号密码以及所链接的逻辑库--> <user name="test"> <property name="password">test</property> <property name="schemas">test</property> </user> <!--只读的用户信息--> <user name="user"> <property name="password">user</property> <property name="schemas">test</property> <property name="readOnly">true</property> </user> </mycat:server>
rule.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://org.opencloudb/"> <tableRule name="rule1"> <!--安装id规则,将id除于1024然后取余,如果余数落在0~512就将数据写到第一个数据库,如果是在512~1024就放到第二个数据库--> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <!--分成两片,每片的区间是512,两个相乘必须是1024--> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2</property> <property name="partitionLength">512</property> </function> </mycat:rule>
以上配置是把id在0~512的数据放在ip1对应的数据库mycat1中的tb_user表中,512~1024的数据放在ip2对应的数据库mycat2中的tb_user表中。
优点 :
1.拆分规则抽象好,join 操作基本可以数据库做;
2.不存在单库大数据,高并发的性能瓶颈;
3.应用端改造较少;
4.提高了系统的稳定性跟负载能力。
缺点 :
1.拆分规则难以抽象;
2.分片事务一致性难以解决;
3.数据多次扩展难度跟维护量极大;
4.跨库 join 性能较差
